
 Hoy cierran sus puertas en la E.T.S. de Ingenieros de Telecomunicación de la Universidad Politécnica de Madrid las jornadas «Big Data, Good Data» de las que os informábamos aquí hace tan solo unos días. Pero para todos aquellos que no habéis podido acudir y, en general, para todos los interesados por saber qué se entiende por «big data», nos hemos reunido con Carlos Herrera, alumno de la UPM que está haciendo su doctorado en torno a esta materia en la Cátedra Orange, que nos da luz sobre este nuevo concepto y sus implicaciones en la nueva sociedad de la información.
Hoy cierran sus puertas en la E.T.S. de Ingenieros de Telecomunicación de la Universidad Politécnica de Madrid las jornadas «Big Data, Good Data» de las que os informábamos aquí hace tan solo unos días. Pero para todos aquellos que no habéis podido acudir y, en general, para todos los interesados por saber qué se entiende por «big data», nos hemos reunido con Carlos Herrera, alumno de la UPM que está haciendo su doctorado en torno a esta materia en la Cátedra Orange, que nos da luz sobre este nuevo concepto y sus implicaciones en la nueva sociedad de la información.
P: Primero de todo, Carlos, ¿qué es el ‘big data’?
R: Empezando por el principio, en Cátedra Orange estamos trabajando en una disciplina totalmente nueva que se ha dado en llamar «Ciencia de las Redes» y cuyo objetivo es intentar predecir los comportamientos de las personas a partir de los datos que tenemos sobre ellas y las relaciones que se establecen entre sí.
En la sociedad tecnológica actual la cantidad de datos que se puede recabar sobre nosotros es enorme. Por ello, cuando empiezas a tratar con tal cantidad de información empieza a interesar estudiarla desde lejos, a nivel de relaciones, y hacer gráficos para interpretar la red que se teje a partir de estos datos. Entre las cosas que podemos representar están, por ejemplo, las relaciones que se establecen en las redes sociales. Pero entendiendo como tales no solo Facebook o Twitter, porque redes sociales ha habido toda la vida ya que las personas siempre se han relacionado. Simplemente Facebook o Twitter lo han hecho más explícito. Estaríamos hablando de cualquier tipo de interacción social.
 P: ¿Y esto cómo se lleva a un gráfico?
P: ¿Y esto cómo se lleva a un gráfico?
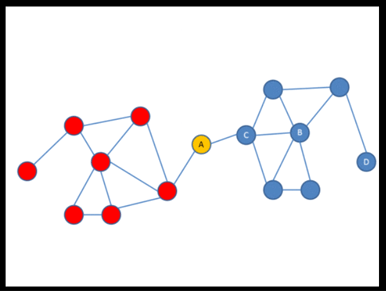
R: Al final de lo que se trata es de de representar de una forma más sencilla y comprensible realidades bastante complejas, establecer redes de relaciones para sacar conclusiones y predecir comportamientos. Me explico: dibujamos a las personas como nodos, círculos, y los enlazamos con líneas si interactúan entre sí. Esto permite ver bastantes cosas, como la forma en la que se relacionan las personas A y D en un gráfico (como el adjunto) o cómo de lejos están estas personas entre sí a nivel de relación en la red. Llegamos a hacer gráficos realmente enormes, tan grandes que no se pueden dibujar. En uno de nuestros últimos estudios trabajamos con información de 7.000 millones de llamadas de usuarios en Francia, España y Portugal. Solo la parte de la red de Francia tenía 18 millones de personas con 81 millones de relaciones. Por eso se llama ‘big data’ 😉
P: ¿Y qué se deduce de estas representaciones?
R: Como decía, lo que hacen estos gráficos es emerger comportamientos que de otra manera no podrías ver. Por ejemplo, hay cosas más obvias como que una red te deja ver cuál es el individuo más popular, el más social, el que habla con más gente. Es los que se llama un ‘hub’, como en los aeropuertos, el que tienen más enlaces. También de hecho se han estudiado las redes de aeropuertos con este esquema para identificar cuellos de botella, para saber los aeropuertos que deberían crecer o que van a crecer en el futuro. Y otras muchas cosas, como redes eléctricas, o la interacción entre genes… Todo son redes. Pero yo me he centrado en las redes sociales, donde los sujetos son personas.
Pero volviendo a nuestro tema, por ejemplo podemos descubrir que un individuo que aparentemente no es muy popular (como el individuo A, representado con un círculo amarillo), porque tiene dos amigos, es curiosamente el único capaz de transmitir información entre el grupo de un amigo y el grupo del otro, lo que le convierte en una persona muy importante en una red. Eso lo llamamos ‘centralidad por intermediación’ o ‘centralidad por cercanía’, porque como está en el centro es la persona que más cerca está de cualquier otra persona de la red.
Y solo es una de las muchas cosas que podemos concluir. Por ejemplo, utilizando llamadas de móvil identificamos a los 50 indiduos más centrales de Francia, España o Portugal y, si se conocían entre ellos, pintábamos un enlace. Lo que vimos es que Francia es un país muy centralizado: o hablas con París o estás en París. Portugal gira casi exclusivamente en torno a Lisboa y Oporto. Y en España pudimos ver cosas tan curiosas como que, más allá de la densidad de población, hay más ‘centrales’ en zonas como Alicante y Murcia que en Cataluña. Esto, con modelos tradicionales basados en densidad de población o cercanía, sería difícil de predecir.
P: Es curioso, pero no termino de ver la utilidad…
R: Creo que el marketing es una aplicación muy clara, porque ahí el ‘big data’ nos sirve para segmentar y hacer campañas más eficaces. Por ejemplo, puedes hacer estimaciones sobre el género y edad de los no clientes de una operadora de telecomunicaciones como Orange simplemente, porque estos no-clientes han hablado con clientes de Orange y se sabe que a determinada edad se habla más con otras personas de determinado rango de edad o sexo.
También se puede deducir qué gente hace más uso del móvil para negocio y quién para uso personal. Hoy es muy común que las personas tengan un mismo móvil para uso particular y de empresa, por lo que es difícil saber si las relaciones que se establecen son más de negocio o personales. Sin embargo, si tú tienes identificados a tus clientes de empresa, puedes deducir que la mayoría de sus relaciones serán de negocio y dirigir a estos no-clientes un campaña con un producto para empresas. Una campaña así tiene más éxito que si contactas al azar, porque se dirige a gente a la que crees que le puede interesar el producto.
Simplemente una anécdota real que lo ilustra: el New York Times contó hace un tiempo una iniciativa de Target, la segunda cadena de distribución más grande en EEUU, que está muy avanzada en ciencia de datos. Ellos sabían que cuando una mujer está a punto de dar a luz, toma determinadas decisiones de compra. Le preguntaron a un experto en ‘big data’ si podía averiguar si una mujer estaba embarazada solo por los datos que disponían de sus clientes a través de los programas de afiliación. Además de otros, el patrón más claro que identificaron es que había unas cremas que se usaban más en la sexta semana de gestación. En otras palabras, solo sabiendo si se compraba esa crema se podía deducir no solo que una mujer estaba embarazada sino también cuándo iba a salir de cuentas.
Basándose en esto lanzaron una campaña de cupones de productos relacionados con bebés para clientes que creían que podían estar esperando un hijo. Al mes llegó un padre muy enfadado a un establecimiento de Target, porque se había mandado uno de estos cupones a su hija adolescente. La cadena pidió perdón por el error y un tiempo después un responsable de Target volvió a llamar a este cliente para reiterar las disculpas. Cuál no sería su sorpresa cuando fue el cliente el que se las pidió, porque resultó que su hija sí estaba embarazada. Es increíble la de cosas que se puede saber de nosotros aglutinando datos entre sí y estableciendo relaciones entre ellos.
‘Big data’, el nuevo petróleo
P: Teniendo en cuenta casos como ése, sorprende un informe reciente de PwC que decía que las empresas aún saben muy poco de sus clientes…
R: Hay un informe de Davos, que dice que el ‘big data’ es el nuevo petróleo pero es que es verdad que hay muy pocas empresas que manejan esto bien actualmente. Hay cuatro que en mi opinión sí lo hacen muy bien y es su ventaja competitiva. La más obvia puede ser Google, que vive de analizar las cosas que hacemos y con quién nos relacionamos, para proponernos publicidad que puede ser de nuestro interés. Este es también el negocio de Facebook, aunque no lo está rentabilizando tan bien. Pero en mi opinión, los mejores ejemplos son Amazon y Netflix. Amazon se ha hecho fuerte en el negocio electrónico por los precios, pero fundamentalmente por los recomendadores asociados a la información que recopila de nosotros por los productos que consultamos o compramos. Y Netflix, que es un servicio de videostreaming que aún no está disponible en España, utiliza un algoritmo increíble porque cuando estás viendo algo en Netflix siempre te sugiere alguna película que te interesa o que has visto.
P: Y cómo sectores, ¿cuáles crees que son los que mejor están utilizando ya el ‘big data’?
R: Yo diría que las ‘over-the-top’ como Google o Facebook, las ‘telco’ y los bancos. Yo creo que toda esa información es muy interesante para las grandes empresas, pero aún no la aprovechan. La información que tiene un banco, por las tarjetas de crédito de sus clientes, les podría ser muy útil. Evidentemente un banco no puede dar datos de sus clientes, pero sí podría decir a otra empresa que quiera abrir una tienda nueva que tiene tantos miles de clientes con tarjeta de crédito en tal código postal y ése puede ser un factor interesante para abrir ese nuevo establecimiento allí, porque son potenciales clientes.
¿Sabes una cosa curiosa que se ha podido saber simplemente analizando las tarjetas de clientes de un banco? Que para lo que las personas estamos más dispuestas a desplazarnos más lejos es para ir a un restaurante. Pues saber eso puede ser interesante si quieres abrir uno, ¿no?
P: Se nota que es un tema que te apasiona…
R: En un artículo del Harvard Businness Review se decía que ser ‘data scientist’, la persona que trabaja con ´big data´, es el trabajo más ‘sexy’ del siglo XXI. Yo no me atrevo a decir tanto, pero desde luego cuando me preguntan digo que es “el más chulo” 🙂
En las jornadas de ayer y de hoy en la UPM se ha estado debatiendo sobre qué podemos hacer con el ‘big data’ y que la sociedad perciba como bueno. «Big data, good data». Es un tema que a mí me motiva mucho.
Cuando estuve en el MIT tuve un profesor, Sandy Pentland, que esta considerado por Forbes uno de los 7 ‘data scientist’ más innovadores del mundo. Nos pidió que desarrolláramos el proyecto de una ‘start-up’ que resolviera un problema para más de 2.000 millones de personas. Básicamente, te dirigía a los países subdesarrollados. Y de ahí salieron ideas muy interesantes, simplemente analizando datos y datos y sacando conclusiones. Un caso que recuerdo se refería a la India, donde hay muchas zonas que no tienen Internet y no parece probable que nadie desplegue infraestructuras para llegar a ciertas zonas. Pues surgió una idea de ‘start-up’ para dar servicios de correo electrónico ‘asíncrono’, con retardo, casi como si fuera ordinario. Se pone un servidor en la aldea y, cada vez que llega el autobús de transporte público a la plaza de la población y que tiene un punto de acceso wifi, todos los correos electrónicos que se han enviado a los habitantes de la aldea les llegan de una vez. Así, con una inversión mínima de quizá una decena de miles de dólares, proporcionas Internet a quizá cien millones de personas.
P: ¿Y las grandes organizaciones supranacionales están haciendo con algo de eso?
R: Sí, hay un proyecto de Naciones Unidas para saber hacia dónde se desplaza la gente cuando hay una emergencia como la que está sufriendo ahora Filipinas. Cuando algo así se produce, la gente huye hacia los distintos campos de refugiados. Sería interesante saber si hay alguna pauta en este sentido, porque mucha ayuda humanitaria se pierde ya que los recursos no llegan dónde está el grueso la gente. En tiempo real se pueden analizar las trazas de móvil para saber hacia dónde van. Hay unos investigadores suecos que mostraron que podían identificarlo con bastante aproximación.
Hay otras cosas que se están estudiando y que no sé si tendrán algún día una utilidad. En EEUU, por ejemplo, se está intentando hacer un sismógrafo basado en Twitter. En los últimos sismos en EEUU los tuits que contienen la palabra «earthquake» van más rápido que la onda sísmica del terremoto. Si el epicentro está en Nueva York y el terremoto fuera a llegar a Chicago, los tuits llegarían antes. No sé si eso servirá en el futuro para algo, pero desde luego es curioso.
Analizar variaciones instantáneas de precios online para crisis alimentarias; poder seguir el IPC al minuto en países con grandes riesgos de inflación… O en el caso de los móviles, cómo te pueden ayudar a estudiar las migraciones estacionales de población en países de África, como Kenia (que curiosamente es el país con más pago por móvil del mundo, a pesar de su situación de subdesarrollo), para poder planificar eficazmente las vacunas… Las posibilidades son infinitas.



