
Si nunca has oído hablar de ellos ya estás tardando porque todo apunta a que los datos sintéticos van a suponer una revolución. Y es que sus aplicaciones son muy variadas, incluyendo la investigación y el entrenamiento de la inteligencia artificial.

Según el informe “The Future of Measurement 2024” (que estudia las últimas tendencias en medición de marketing), precisamente una de ellas es el importante crecimiento de los datos sintéticos asociado a la masiva adopción de la inteligencia artificial.
En concreto, basándose en datos de la consultora Gartner afirman que hasta el 60% de los datos utilizados en proyectos de IA y análisis serán sintéticos y, según Straits Research, el mercado global de generación de datos sintéticos crecerá un 37% entre 2023 y 2031.
Estos datos dan una idea de la importancia que va a cobrar este ámbito que nos proponemos abordar comenzando por el principio.
¿Qué son los datos sintéticos?
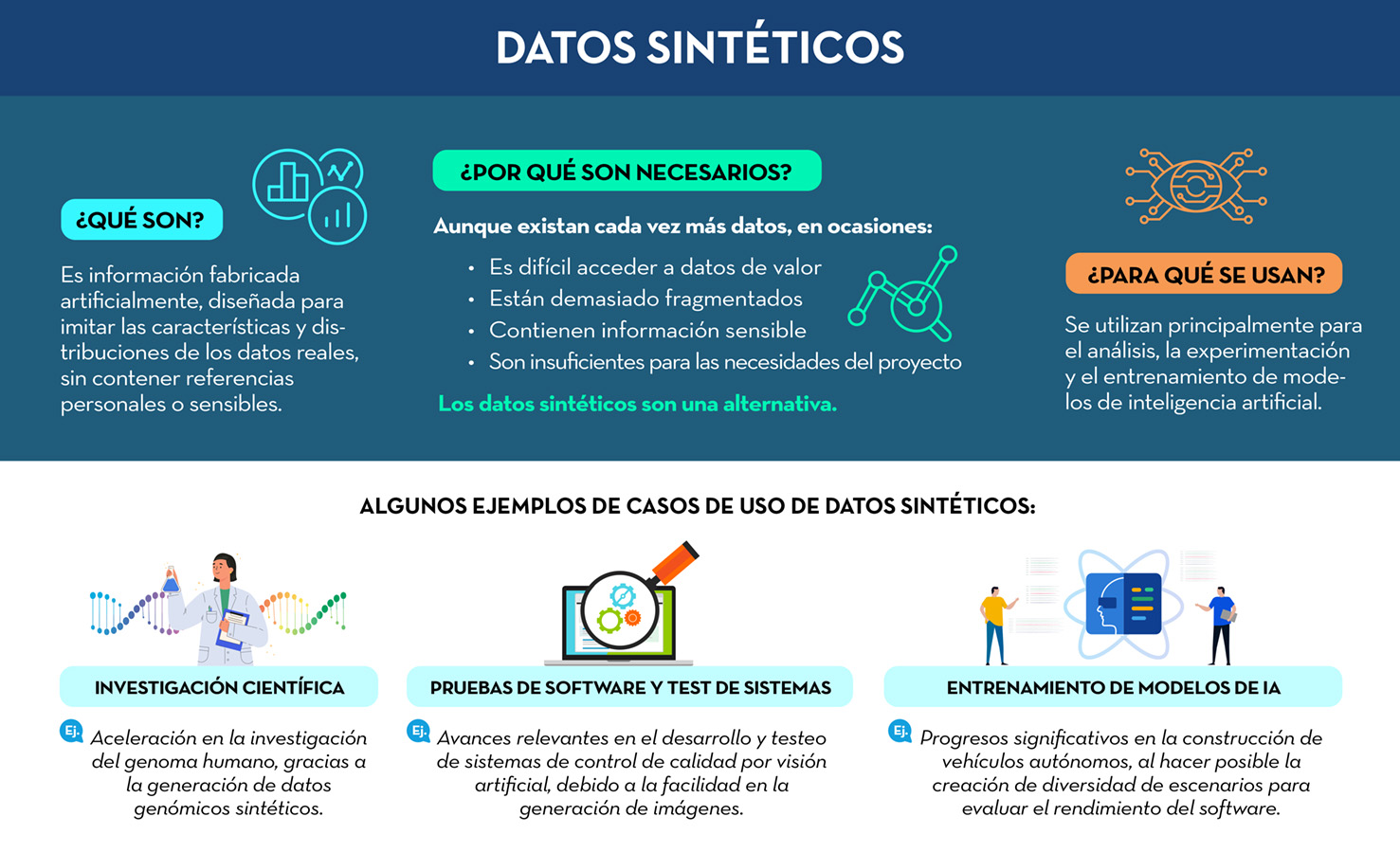
Tal y como nos cuenta el Ministerio para la Transformación Digital en su web datos.gob.es, los datos sintéticos son información fabricada artificialmente que imita las características y distribuciones de los datos reales, sin contener información personal o sensible.
Estos datos se generan mediante algoritmos y técnicas que preservan la estructura y las propiedades estadísticas de los datos originales. En otras palabras, los datos sintéticos son ficticios, como copias artificiales de datos reales, pero sin la información personal que podría poner en riesgo a las personas.
Esto los hace muy útiles en situaciones donde la disponibilidad de datos reales es limitada; por ejemplo, si se quiere desarrollar un nuevo algoritmo de detección de fraudes y se opta por usar datos sintéticos de manera que no sea necesario exponer información financiera confidencial de los clientes.
Por otro lado, también ayudan a proteger la privacidad de las personas, al usarse en áreas como la atención médica o la investigación financiera, donde es crucial proteger la identidad de los individuos.
¿Cómo se generan los datos sintéticos?
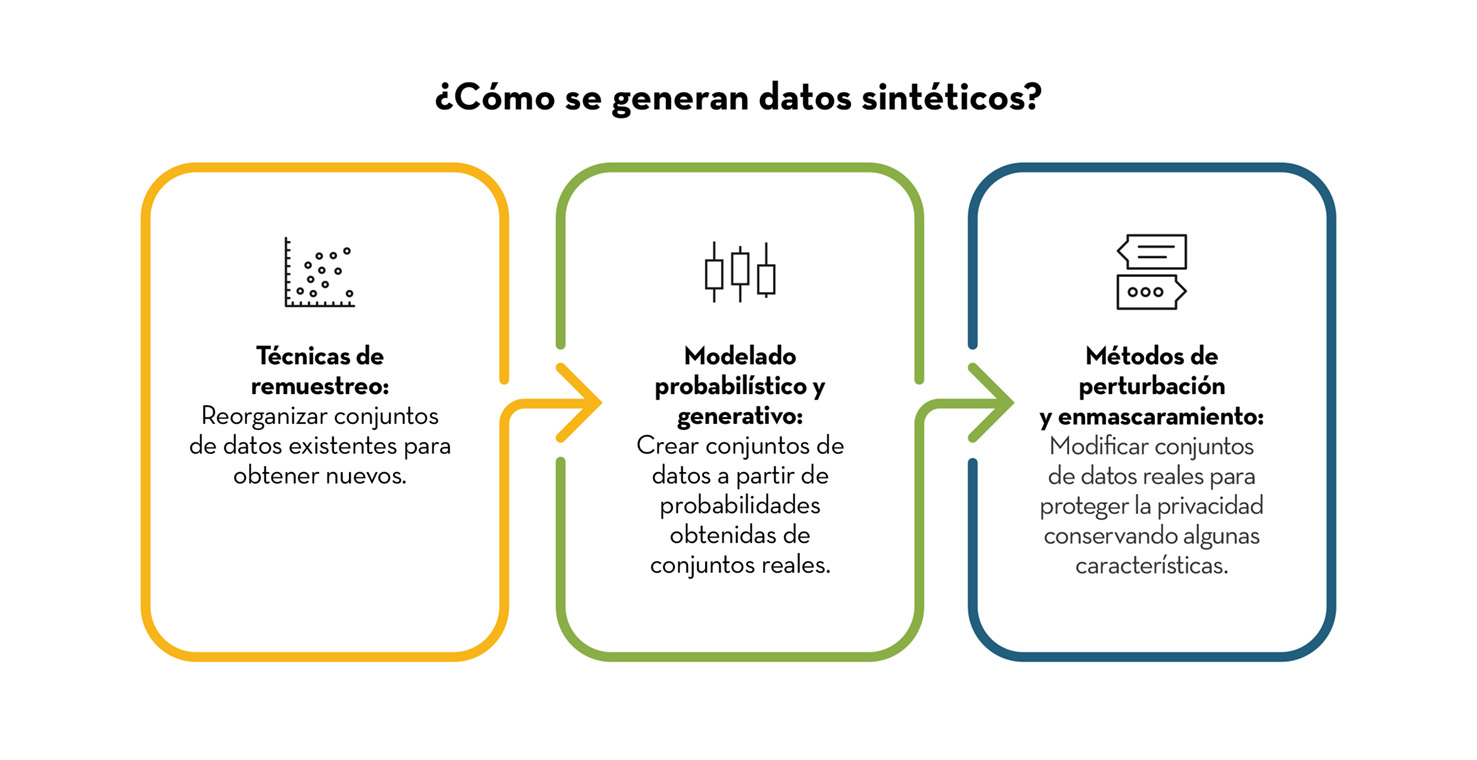
Existen diversas técnicas para generar datos sintéticos, incluyendo las siguientes:
- Modelado estadístico: Se utilizan modelos matemáticos para crear datos que sigan las mismas distribuciones de probabilidad que los datos reales.
- Aprendizaje automático: Algoritmos de aprendizaje automático se entrenan con datos reales para aprender las relaciones entre las variables y luego generar nuevos datos que sean consistentes con esas relaciones.
- Simulación por computadora: Se crean simulaciones de escenarios del mundo real para generar datos que reflejen el comportamiento de esos escenarios.
¿Para qué se utilizan los datos sintéticos?
Los datos sintéticos tienen una amplia gama de aplicaciones, aunque en este documento del Ministerio para la Transformación Digital se enumeran las que consideran tres principales:
Investigación científica
Los datos sintéticos permiten a los investigadores explorar y desarrollar nuevos enfoques, modelos y algoritmos sin la necesidad de acceder a datos reales sensibles, lo que acelera la investigación y al tiempo mantiene la integridad y privacidad de los participantes en los estudios.
Como ejemplo, se usan en el campo de la investigación con datos genómicos, uno de los tipos de datos más complejos, multidimensionales y ricos en información del mundo. Un ámbito en el que los investigadores se enfrentan a una disponibilidad muy escasa de datos debido a las estrictas regulaciones de privacidad y las restricciones en torno a los datos genéticos humanos.
Pruebas de software y test de sistemas
Los datos sintéticos se usan ampliamente para probar y validar software y sistemas informáticos. Al generar conjuntos de datos realistas, pero sintéticos, los desarrolladores pueden simular escenarios diversos y evaluar el rendimiento, la escalabilidad y la seguridad de sus aplicaciones sin exponer datos reales ni correr riesgos innecesarios.
Por ejemplo, pueden usarse en el desarrollo y testeo de un sistema de control de calidad por visión artificial, donde resulta más fácil generar artificialmente cien mil imágenes de algún producto concreto que tener que recopilarlas del mundo real una por una.
Entrenamiento de modelos de inteligencia artificial
Finalmente, los datos sintéticos son esenciales en el entrenamiento y la mejora de modelos machine learning (o de aprendizaje automático); es decir en los que se basan las —tan de moda últimamente— asistentes virtuales como ChatGPT, Llama o Gemini.
Por ejemplo, a la hora de entrenar la inteligencia artificial usada en un vehículo autónomo es crucial usar datos sintéticos que puedan aportar todos los datos necesarios para construir uno verdaderamente seguro. Y es que recopilar del mundo real los datos de conducción necesarios para recrear cada escenario que se podría encontrar en una carretera sería algo, sencillamente, imposible.

Estos serían los tres usos principales que se están dando a este tipo de información sintética, aunque además apuntan otros casos de aplicación donde son esenciales los datos sintéticos: detección de fraudes, medicina preventiva, evaluación de riesgos crediticios, gestión de siniestros en el campo de los seguros…
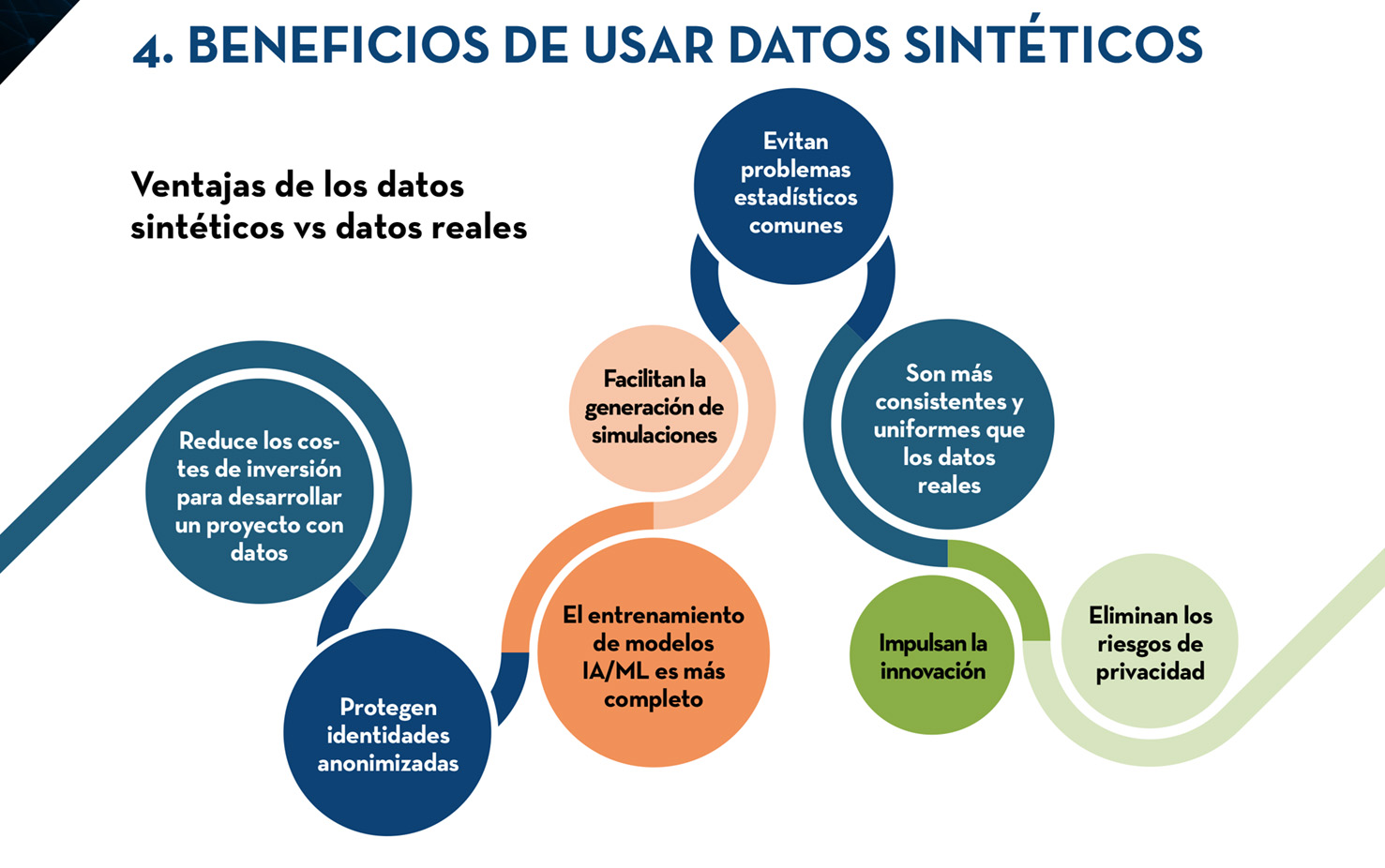
¿Cuáles son las ventajas de los datos sintéticos?
Los datos sintéticos ofrecen un conjunto de beneficios que los convierten en una herramienta valiosa en diversos sectores. Entre las principales ventajas encontramos:
- Protección de la privacidad: Al ser creados artificialmente, los datos sintéticos no contienen información personal identificable (PII), lo que garantiza el cumplimiento de las regulaciones de privacidad como el RGPD. Esto permite a las empresas trabajar con datos confidenciales o sensibles sin comprometer la privacidad de las personas.
- Aumento de la diversidad de datos: Pueden usarse para generar conjuntos de datos más diversos y completos que reflejen mejor la población real. Esto es particularmente útil en áreas donde los datos reales son escasos o están sesgados hacia ciertos grupos demográficos.
- Aceleración del desarrollo y las pruebas: Permiten a las empresas crear entornos de prueba seguros y escalables para desarrollar y probar software, sistemas y algoritmos de IA sin necesidad de utilizar datos reales. Esto agiliza el proceso de desarrollo y reduce costos.
- Mejora de la precisión de los modelos de IA: Los conjuntos de datos sintéticos cuidadosamente diseñados pueden mejorar la precisión de los modelos de IA al entrenar con escenarios y casos extremos que son difíciles o costosos de recopilar en el mundo real.
- Reducción de costos: La generación de este tipo de datos artificiales puede ser más económica que la recopilación y el etiquetado de datos reales, especialmente en casos donde los datos son escasos o difíciles de obtener.
- Mayor control y consistencia: Ofrecen un mayor control sobre las características y distribuciones de los datos, lo que permite a las empresas crear conjuntos consistentes y adaptados a sus necesidades específicas.
- Reducción del sesgo en los datos: La data sintética puede utilizarse para mitigar el sesgo en los conjuntos de datos reales al generar información que represente de manera justa a diferentes grupos demográficos o perspectivas.
- Facilita la colaboración: Pueden compartirse de forma segura entre diferentes equipos y organizaciones sin la necesidad de preocuparse por las violaciones de privacidad o la confidencialidad.
- Permite realizar experimentos y análisis: Trabajar con datos sintéticos posibilita la realización de experimentos y análisis que serían inviables o éticamente cuestionables con datos reales.
- Promueve la innovación: Abren nuevas posibilidades para la innovación en diversos campos, como la investigación científica, el desarrollo de productos y la creación de experiencias personalizadas.
¿Y cuáles son los riesgos asociados a los datos sintéticos?
A pesar de sus numerosas ventajas, es importante considerar los posibles riesgos asociados al uso de datos sintéticos:
- Posible sesgo: Si se generan a partir de conjuntos de datos reales sesgados, podrían perpetuar o amplificar esos sesgos en los modelos o análisis que se entrenan con ellos.
- Dificultad para detectar errores: Los datos sintéticos pueden ser muy realistas, lo que dificulta la detección de errores o anomalías en los datos. Esto podría llevar a conclusiones erróneas o decisiones incorrectas basadas en esos datos.
- Falta de generalización: Los generados a partir de un conjunto de datos limitado podrían no generalizarse bien a situaciones del mundo real que no se tuvieron en cuenta durante la creación de los datos.
- Potencial de reidentificación: En algunos casos, los datos sintéticos podrían ser reidentificados y vinculados a individuos específicos, lo que representa un riesgo para la privacidad.
- Dependencia de la calidad de los datos originales: Su calidad depende en gran medida de los datos reales utilizados para generarlos. Si son inexactos o incompletos, la información sintética también lo será.
- Consideraciones éticas: Su uso plantea interrogantes éticos en torno a la creación y manipulación de datos artificiales que simulan la realidad. Es importante establecer marcos éticos claros para su uso responsable.
- Falta de regulación: Actualmente no existe una regulación específica para el uso de datos sintéticos, lo que crea un vacío legal y podría generar problemas en el futuro.
- Costos de implementación: La generación de datos de alta calidad puede requerir una inversión significativa en tecnología y recursos, lo que no pueden permitirse todas las empresas o instituciones.
- Dificultades en la interpretación: Pueden ser complejos de interpretar y analizar, lo que requiere personal con las habilidades y conocimientos adecuados.
- Posible uso para fines malintencionados: Podrían ser utilizados con fines malintencionados, como la creación de noticias falsas o la suplantación de identidad.

Por todo ello, es importante ser conscientes de los riesgos asociados a estos datos artificiales y tomar medidas para mitigarlos, como emplear métodos de generación de datos sintéticos sólidos y confiables e implementar controles de calidad estrictos para garantizar su precisión y confiabilidad. También, muy importante, considerar cuidadosamente la ética respecto al uso de datos sintéticos.
En cualquier caso, espero que os haya quedado clara la importancia de los datos sintéticos y cómo son una herramienta poderosa y con un gran potencial para muy diversas aplicaciones. Y lo será cada vez más en el futuro próximo.
Imágenes | Fotos de datos.gob.es, Warc y Freepik






